Part 1: Scale your system Part 1: From 1 to 99 999 users
We are onto the 2nd part. How do we continue scaling from 100 000 users onwards?
In this post
Stage 4: 100 000 active users
Now it might be time for a CDN and a Stateless architecture.
What can be gained by using a CDN?
CDNs offer a network of geographically dispersed servers. The more physically closer the servers are to your users, the shorter the latency is. First-generation CDNs served only static resources: images, css, javascript, …, but currently, the more advanced CDNs can also deliver dynamic content that is unique to the requestor and not cacheable. But these are already very advanced CDNs. A basic CDN still serves only static resources.
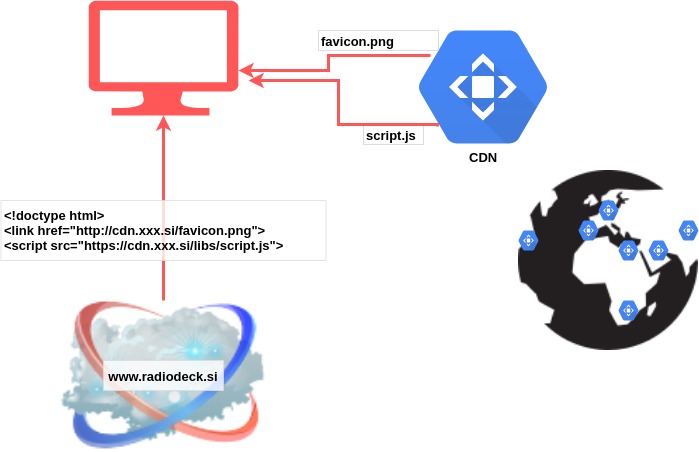
CDNs make sure that when a user connects to a website, the closest and the best performing server will deliver the static resources for this website. With a basic CDN, the website is still served via your load balancer, but all the static resources (images, css, …) are served from CDNs.
Initially, if a file changed, you needed to explicitly push it to the CDN. Then, something called “origin pulling” became a thing. This meant the refresh of a file became automatic. When a user requested a resource, the CDN looked into its cache and if the resource was outdated or not there, it fetched the resource from the original website.
This means, you could use your CDN, to cache certain pages of Radiodeck, which will continue to be live even if your own servers are down.
Some CDNs specialize in security. Similar to load balancers, CDNs are also one of the first recipients of traffic and can thus detect DDoS or other attacks and block them.
What is stateless architecture? Weren’t we stateless already?
At first glance, you might think: “What state? Are we storing any state?”. It might not be immediately evident, but there indeed is some state, we are managing outside of a database, it is the session.
Storing information in the session means that requests share data. A user logs in one request, but her information is then accessible to all subsequent requests. Since the session is not stored in the database, but in a particular web server’s files, all requests from the same user must be processed by the same web server.
In our Radiodeck example, this means that our load balancer needs to remember to which server it sent each request. With enough traffic, this can become a bottleneck.
A solution for this is a so-called stateless architecture. We still need the session information, but just like with other website data, we store it in a database. This time, however, it is important that access to the session data is efficient. The data is also not relational nor structured, each session object is completely independent of the others and might be structured completely differently. This makes session storage the perfect candidate for a NoSQL database type.
The session database can be Memcached or Redis, which we have already talked about or any other type of NoSQL database.
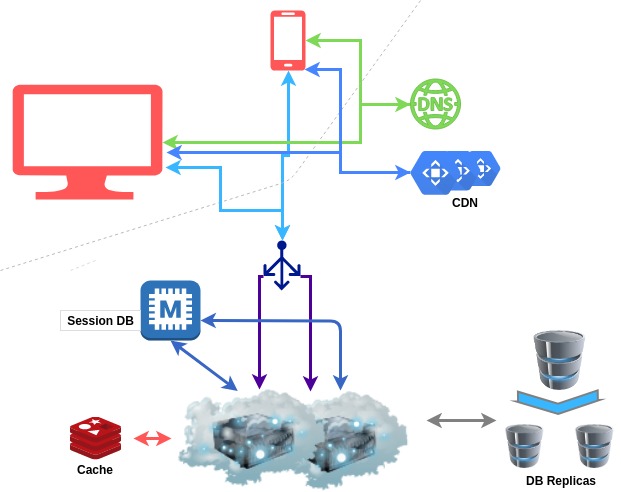
Stage 5: 500 000 active users
It might be time to split up your web servers into different locations around the world. Having several physical locations from where you can provide your Radiodeck’s services has the similar advantages as using a CDN, a lowered latency for your users all around the world, but it also adds redundancy to your system. Should one of your locations experience serious issues, then you can simply redirect traffic to a different location.
Of course, this makes all the existing problems we’ve talked about much worse. Synchronizing data among all the different locations is ever more challenging. Keeping files up to date, keeping permissions up to date, keeping the session up to date, user history, … .
Stage 6: 1 000 000 active users
We’ve scaled all kinds of aspects of our architecture, but as you see there is basically 1 rule to scaling. Divide, isolate, cut off. Whenever we wanted to scale anything, we isolated it from the rest and defined a very narrow communication protocol between the old part and the cut-off part. This always gave us the ability to then scale both pieces independently from each other.
A key tool to achieve this Message queueing.
Message queues
We have ended up with a lot of separate pieces in our system, which still need to communicate with each other. The goal is to make this communication independent of the services which use it. Thus we define message publishers, message subscribers and queues of messages.
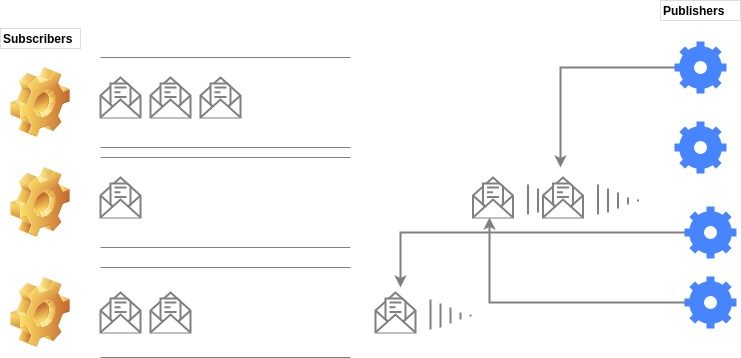
Message queues are again making our system more decoupled, which makes it more scalable. It also gives us the possibility to schedule an action for a slightly later time (when the server deals with all the already scheduled actions) while the app can continue functioning unencumbered. And should an action be splittable, we can simply split it, send it off and rely on the fact that the action’s parts will eventually be executed.
Stage 7: 50M active users
At 50M users, your DB is surely starting to give up. We are again facing the question: Do we scale up or out. Maybe the answer is both. But what does scale-out look like in databases?
Vertical partitioning (not the same as vertical scaling)
Vertical partitioning describes the process where the database is split along tables or along columns. Some tables (or some columns of a table) go into database A, others into database B. You would separate data by functionality. All the data you need for 1 sort of operations goes to database A, the rest to database B.
The problem with this approach is that such a split might not be enough, but on the other hand, it is also difficult to split data in this way effectively. It will be very difficult to do joins across databases if you end up needing data from several databases.
Horizontal partitioning/sharding
In this case, the tables are separated by row, tables are split into chunks along rows and each chunk is saved in a different database. Let’s say you have 1 table for all your users. You wish to shard this table. You have to first decide what is going to be your key. The key can be a single indexed field or an indexed compound. Let’s say we’ve chosen the user.id to be our sharding key. Since we plan to split our database into 3, we will do user.id % 3 and end up with:
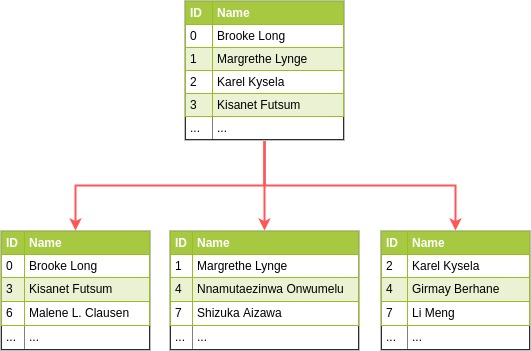
When choosing a sharding key, it is important to make sure the data will thus be split evenly. But there are 2 aspects of “evenly” to consider. First, we want the GB of data in each shard to be similar and we want data to grow at a similar rate in each shard. Secondly, we also strive for the number of connections per second to each shard to be roughly the same. We might have millions of users, but maybe only 1000 of them create 10% of traffic.
Once a DB has been sharded, it is difficult to perform joins across multiple servers. To solve this problem, databases are often de-normalized. This way the joins are replaced by queries to just 1 table.
Stage 8: 100M active users
This is where we are at:
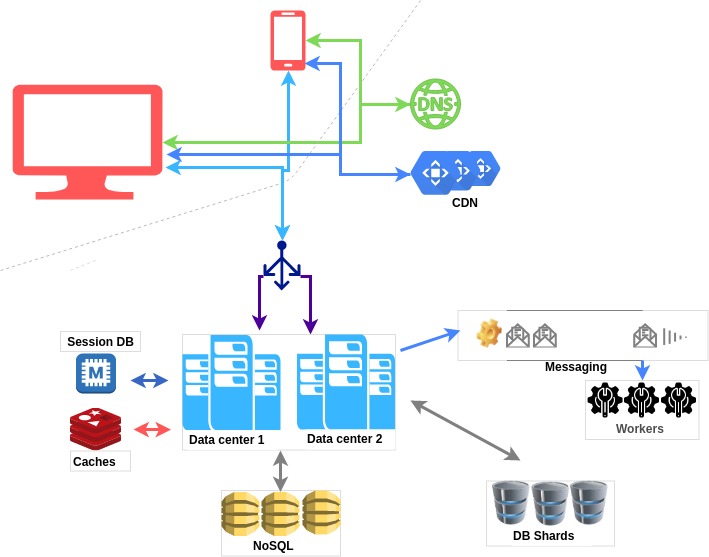
At this point, you could be improving our DB. You could put some data into a NoSQL database and make access to it quicker. You would need to monitor the system more closely and fine-tune the least performing parts. You will want to develop your own approaches and solutions.
Scaling is a never-ending process. To be able to scale bigger and bigger, we need to be able to divide something big into smaller pieces, but still, keep the functionality equal. However, everything is a trade-off. The bigger the system, the more moving parts it has and thus the more things can go wrong. Highly distributed systems are a good solution for huge, take-over-the-world projects, but they demand a lot of upkeep and a lot of backup plans. Sometimes it is still better to stay small and nimble.
External sources
- Content Delivery Network (CDN) Caching
- What Is a CDN and How Does It Work?
- Where does session save?
- Active-Active for Multi-Regional Resiliency
- Distributed Systems in One Lesson by Tim Berglund
- Data Partitioning: Vertical Partitioning, Horizontal Partitioning, and Hybrid Partitioning
- What is database sharding?