What do a good portion of database transactions do? They fail. But this is hardly surprising.
The whole reason we put the code into a transaction is because we expected to encounter some failures.
DB transactions give us the ability to handle failures gracefully and ensure our DB isn’t left in an inconsistent state. Wrapping them around some code is a crucial first step towards this goal. But did you know there is a second step in this process?
There are actually at least 4 possible second steps:
- give up
- log the error and then give up
- ask the user for input
- retry <- my personal favorite 💝
Most code just gives up
The msg “use DB transactions” is spread far enough that transactions are present in most codebases (where applicable, of course). But then, there is no error handling, no retry, no nothing.
At most, they leave behind just a sad log message, alla Oh-oh, DB transaction failed.. Maybe it’s accompanied by the DB error message, possibly (but probably not) by
a stack trace and (very likely) by some indecipherable DB-state gibberish thrown in for good measure.
But after the log msg the function / request / task just ends.
Example:
def crud_something(**kwargs):
do_first_few_things()
Transaction.start()
try:
write_something_to_db()
Transaction.commit()
except DatabaseError as exc:
# If anything went wrong, we just rollback EVERYTHING and raise an exception
# Surely somebody else will then handle this exception, right?
Transaction.rollback()
logger.error("Could not do Z, a DB error has happened", exc_info=exc)
raise # ← re-raise the exception
do_more_stuff() # ← This will never run if the DB transaction fails
The next best thing is asking the user for input …
… or at least telling them that the action failed 🤠.
Here and there, I sometimes see code that actually handles the DB error and propagates it to the user in some shape.
Mostly as a sad message, like Sorry, something went wrong. Please try again later..
Occasionally, I get to enjoy a more actionable message, like Sorry, the <object X> has already been deleted, please refresh the page..
The matching code being something like:
def delete_something(**kwargs):
do_first_few_things()
Transaction.start()
try:
write_something_to_db()
Transaction.commit()
except DatabaseError as exc:
Transaction.rollback()
logger.error("Could not do Z, a DB error has happened", exc_info=exc)
# -------- NEW CODE --------
# Tell the user what happened
if isinstance(exc, ObjectDoesNotExist):
raise ActionError(
"Sorry, the <object X> has already been deleted, please refresh the page."
) from exc
raise ActionError("Sorry, something went wrong. Please try again later.") from exc
# --------------------------
do_more_stuff()
But when a piece of code is really important …
… and is frequently run and has caused lots of transaction fails in the past and time has been allocated to fix this problem, that’s when devs finally get creative.
What do devs do, when they get creative? They write if statements and start thinking about all the things that can go wrong in the code. 🖌️
Every DB transaction is different because it is trying to achieve a different goal. So, each one needs custom error handling.
The general guideline is to list all the scenarios in which your DB transaction can fail and then craft a particular error handling for each one.
However, there are 3 main kinds of transactions:
- a) the ones that can be retried and then succeed
- b) the ones that don’t need to be retried because their goal was already achieved by another transaction
- c) the ones that can’t be retried because they can never succeed
(It’s funny, how there’s usually more than 2 kinds of everything, isn’t it?)
The ones that can be retried
The best example of this type of code is chain-building code. Code that attaches a new item to a list of items.
When such a DB transaction fails, it often fails because 2 threads are trying to append an item at the same time.
Only one can succeed. The other should wait a bit, but then it can be retried and it will succeed.
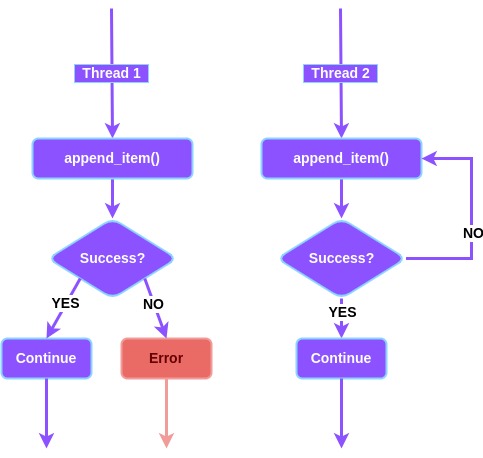
This pattern also fits very well with PostgreSQL’s advisory locks: you start a transaction, and then request an advisory lock, but the timeout is reached before the lock is granted. You can then retry the transaction.
The ones that don’t need to be retried
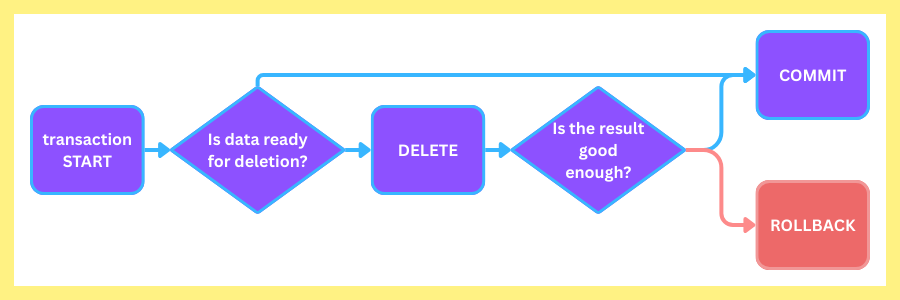
An example of this is deletion.
Imagine we run a DB transaction that deletes an object, but the DB transaction fails with the message that the object doesn’t exist in the DB.
Assuming we don’t have a bug in our code, we can safely return that the object has been deleted.
The code can safely treat this kind of DB error as a success.
The ones that can’t be retried
These are the “un-salvageable” transactions. Once it fails, it fails. The only way for it to succeed is to change the data.
For instance: you want to create a new user, but another person just registered the same username. Nothing that can be done here, but to ask the user for a different username.
But, code (that creates DB transactions) is very pliable
We can mould it, to some degree, to make it fit the shape we want.
I like the code pattern of retrying the transaction-code. So, I mould lots of code with DB transactions into this shape.
I do this by adding some error handling inside the transaction. That way I can re-call the whole function, if the transaction fails.
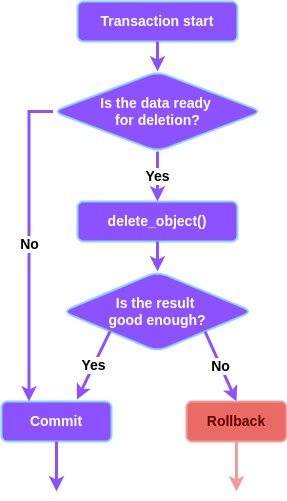
In practice this is achieved by:
- using
get_or_createandupdate_or_createinstead of justcreate - catching write exceptions on write operations (anticipating 2 threads trying to write the same thing)
- checking if an object is as we think it is before we change it (ie: does it exist, before we delete it, or is its owner really NULL before we set the owner. For the last example, you could use
update ... where ... and owner is NULLand then check what the response was.) - catching the obvious exceptions like “object does not exist”
- refreshing data after acquiring a lock (it’s possible we were waiting for a bit before we acquired the lock and another thread already changed DB data)
- checking if another thread already did our work
- … (whatever works for your code)
It’s still very custom to what your code is actually doing.
A decorator was born @in_transaction_with_retry
And because I’m putting things into DB transactions a lot, I’ve built myself a retrying decorator for Django.
I’m not a fan of Django. Just felt really strongly to add this disclaimer. 😆 But I do work with it a lot.
I just:
- put my transaction code into a function
- add the
@in_transaction_with_retrydecorator - and select the number of retries
Like so:
@in_transaction_with_retry(action_desc="deleting something", max_retries=5)
def delete_something(**kwargs):
...
from functools import wraps
from typing import Any
from typing import Callable
from typing import NoReturn
from typing import TypeVar
from typing import cast
from django.db import transaction
from django.db.utils import DatabaseError
logger = logging.getLogger(__name__)
class RetriesExceeded(DatabaseError):
pass
F = TypeVar("F", bound=Callable[..., Any])
class in_transaction_with_retry:
"""Wrap the function into a transaction. And re-try the function up to `max_retries`+1 times."""
def __init__(
self,
*,
action_desc: str,
# ↑ Let's require an identifier. The error msg will be more helpful this way.
max_retries: int = 5,
# ↑ We will run the code at most `max_retries`+1 times.
):
self.action_desc = action_desc
self.max_retries = max_retries
assert self.max_retries >= 1
def __call__(self, function: F) -> F:
@wraps(function)
def wrapped_trans(*args, **kwargs):
db_exc: DatabaseError | None = None
num_of_attempts = self.max_retries + 1
attempt: int = -1
for attempt in range(1, num_of_attempts + 1):
logger.debug(f"Attempt {attempt=}/{num_of_attempts} of {self.action_desc}")
try:
with transaction.atomic():
return function(*args, **kwargs)
except DatabaseError as exc:
db_exc = exc
# Just a little hook if I need to subclass this decorator
self._custom_exception_handling(db_exc, attempt)
if self._is_a_deadlock_error(exc):
logger.exception(
"Attention, a deadlock has happened. Maybe this is totally fine and we are restarting "
"the afflicted transaction, but maybe this is not fine. Check the pg logs.",
exc_info=exc,
stack_info=True,
extra=dict(action_desc=self.action_desc),
)
else:
logger.warning(
f"DatabaseError happened while `{self.action_desc}` {attempt=}/{num_of_attempts}",
exc_info=exc,
stack_info=True,
extra=dict(action_desc=self.action_desc),
)
assert db_exc
self._raise_action_failed_exc(db_exc, attempt)
return cast(F, wrapped_trans)
def _raise_action_failed_exc(
self,
db_exc: DatabaseError,
attempt: int,
) -> NoReturn:
log_msg = f"Ran the action `{self.action_desc}` {attempt} time(s), could not succeed."
raise RetriesExceeded(log_msg) from db_exc
def _is_a_deadlock_error(self, exc: DatabaseError) -> bool:
return "deadlock detected" in str(exc)
def _custom_exception_handling(self, db_exc: DatabaseError, attempt: int) -> None:
"""Override this function to extend this class's behavior"""
And no, this decorator can’t be turned into a context manager. A context manager can yield only 1x. And we need to yield inside a for-loop, so.. no context manager for us.